
| 论文名称 | 研究主题 | 主要内容梳理 | 具体做法 | | — | — | — | — | | A COMPREHENSIVE SURVEY OF LLM ALIGNMENT TECHNIQUES: RLHF, RLAIF, PPO, DPO AND MORE | 大语言模型对齐技术综述 | 1. 点明大语言模型(LLMs)发展中存在生成非期望响应的问题,强调对齐的重要性,提出对相关方法分类综述的需求。
2. 从奖励模型、反馈、强化学习、优化四个维度阐述LLM对齐技术的核心要素与研究方向。
3. 详细回顾多篇论文,对比不同方法在各维度的差异。
4. 展望未来研究方向,涵盖统一评估任务、扩展方法应用规模、研究二进制反馈和AI反馈、加速Nash学习、确定迭代学习终止条件、简化SFT + 对齐过程等方面。 | 1. 奖励模型:剖析显式与隐式、点式与偏好式、响应级与令牌级奖励模型以及负偏好优化的原理与应用。
2. 反馈:探讨偏好反馈与二元反馈、成对反馈与列表反馈、人类反馈与AI反馈的特点及应用场景。
3. 强化学习:研究基于参考与无参考的RL、长度控制RL、不同散度的RL、在线与离线策略RL的技术要点。
4. 优化:讨论迭代/在线与非迭代/离线偏好优化,以及分离与合并SFT和对齐的方法及优劣。
5. 对比论文:InstructGPT借助人类偏好微调;RLAIF - Anthropic利用AI反馈优化;DPO直接运用人类偏好数据进行优化等。 | | Reinforcement Learning Enhanced LLMs: A Survey | 强化学习增强大语言模型 | 1. 阐述强化学习增强LLMs的研究现状、训练步骤,指出其复杂性及缺乏综述的现状。
2. 介绍强化学习基本概念及其在LLMs中的应用模式。
3. 列举流行的强化学习增强LLMs并分析其特点。
4. 深入分析RLHF、RLAIF及直接偏好优化(DPO)等技术。
5. 探讨现有方法面临的挑战及未来改进方向。 | 1. 强化学习基础:明确关键术语和通用流程,并将其映射到LLMs框架中。
2. 流行模型:介绍DeepSeek - R1、Kimi - k1.5等模型如何利用强化学习提升性能。
3. RLHF和RLAIF:分别阐释其训练过程和关键数据集。
4. DPO方法:探究SLiC - HF、β - DPO等利用偏好数据优化LLMs的具体策略。 | | Reinforcement Learning with Human Feedback: Learning Dynamic Choices via Pessimism | 动态离散选择模型下的离线强化学习与人类反馈 | 1. 提出在动态离散选择模型下从人类选择学习最优策略的问题,介绍相关研究工作。
2. 详细阐释动态选择悲观策略优化(DCPPO)算法。
3. 分析算法在不同模型类(线性模型MDP和RKHS)下的性能表现。
4. 证明算法在样本复杂性方面的有效性。 | 1. DCPPO算法:运用最大似然估计(MLE)来估计人类行为策略和状态 - 动作价值函数;借助学习到的价值函数,通过最小化贝尔曼均方误差来恢复人类奖励函数;将学习到的奖励函数代入,利用悲观价值迭代找到接近最优的策略。
2. 性能分析:在仅单策略覆盖数据集的情况下,证明算法的次优性在依赖分布转移和维度方面与经典悲观离线RL算法相近。 |
| ——– | ——– | ———— | ——– | —- | —- | —- | —- | —- | —- | ———————————————————— | ———————- | ———————————————————— | ———————————————————— | —- | ————————————————– | ———————- | ———————————————————— | ———————————————————— | —- | ———————————————————— | —————————————— | ———————————————————— | ———————————————————— |
参考文献:
- A COMPREHENSIVE SURVEY OF LLM ALIGNMENT TECHNIQUES: RLHF, RLAIF, PPO, DPO AND MORE
- Reinforcement Learning Enhanced LLMs: A Survey
- Reinforcement Learning with Human Feedback: Learning Dynamic Choices via Pessimism
论文概述
奖励模型
RLHF 的原始工作中衍生出了点态奖励模型,该模型在给定提示x 和响应y 时返回一个奖励分数,即r ( x, y )。
*点态奖励模型 vs. 偏好性模型* RLHF 的原始工作中衍生出了点态奖励模型,该模型在给定提示x 和响应y 时返回一个奖励分数,即r ( x, y )。给定来自提示的两个点态奖励分数,一个期望的响应和一个不期望的响应r ( x, y_w ) 和r ( x, y_l ),基于 Bradley-Terry (BT) 模型[38],可以得到期望响应优先于不期望响应的概率P ( y_w > y_l | x )=\sigma( r ( x, y_w )-r ( x,y_l ) ) 。然而,这种方法存在劣势,因为它无法直接获得成对偏好,也无法适应人类标注中的不一致性。为了解决这个问题,提出了 Nash 学习方法,直接对 P(π > π’) = E_x∼ρE_y∼π(y|x),y’∼π’(y|x) [P(y > y’ |x)] 进行建模。
token级别与response级别
在原始数据集中以三元组形式收集,即{x, y_w, y_l },奖励是按响应给出的。因此,在 RLHF 和 DPO 中,奖励是在响应级别构建的;在马尔可夫决策过程 [39] 中,奖励是在每个动作之后给出的,导致状态的变化。为了在每个动作之后实现对齐,引入了token级奖励模型
负偏好优化
在 RLHF 数据集中,人类标注了期望和不期望的响应。最近,随着 LLM 能力的进步,一些研究人员提出,LLM 可以生成比人类标注者更高质量的期望响应。因此,他们选择仅使用收集数据集中的提示和不期望响应,利用 LLM 生成期望响应
反馈
反馈包括来自人类或\mathbfA I的偏好和二元响应,无论是成对还是列表形式。这里论文将讨论三个关键区别:
- 偏好反馈与二元反馈;
- 成对反馈与列表反馈;
- 人类反馈与AI反馈。
偏好反馈与二元反馈
在RLHF论文中,收集了偏好反馈,即y_w > y_l。然而,随后的工作如KTO和DRO提出,收集偏好反馈较为困难,而收集二元反馈的另一种形式是二元反馈,指的是简单的“赞”(积极,即y+)或“踩”(消极,即y^-)response
**成对反馈 vs. 列表反馈*
对于K 个不同的响应y_1, y_2, …, y_K,成对反馈涉及将x 与每个标签配对。列表反馈则涉及对K 个响应进行C_K^2 次成对比较。然而,后续工作如 LiPO 提出,将列表偏好视为排序问题而不是多个成对偏好更为有利
*人类反馈 vs. AI 反馈*
在 RLHF 中,反馈来自被要求在同一提示下对多个响应提供偏好的人类。然而,这一过程已被证明既繁琐又昂贵。随着 LLMs 的最新发展,收集 AI 反馈以对齐 LLMs 已成为可能
RL训练
关于 RL 的讨论分为四个子主题:1) 基于参考的 RL 与无参考的 RL,2) 长度控制 RL,3) RL 中的不同散度,4) 在线 RL 与离线 RL
基于参考的 RL 与无参考的 RL
RLHF中强化学习目标的一个关键目标是使当前策略即πtheta 与参考策略即 πref 之间的距离最小化。因此,大多数方法都聚焦于基于参考的策略。然而,引入参考策略带来了显著的内存负担。为了解决这一问题,提出了多种方法来避免使用参考策略。例如,SimPO 提出了一种不同的目标函数,完全避免了参考策略的需求。
长度控制 RL
| 在使用 LLM 作为评估器时,观察到它们倾向于偏好冗长的回复,即使没有提供额外的信息 [40]。这种偏差可能影响 LLM 的对齐。此外,LLM 回复的冗长性可能增加人类阅读和理解所需的时间。原始的强化学习目标并未考虑这一问题,但后续工作如 R-DPO 和 SimPO 引入了对长度控制的考虑,其中 | y | 表示输出回复的长度。 |
RL 中的不同散度
| 在 RLHF 中,反向 Kullback-Leibler(KL)散度,即D_K L 常用于衡量当前策略π_theta ( y | x ) 与参考策略π_ref( y | x ) 之间的距离。然而,KL 散度已被发现会降低回复的多样性。为了解决这一问题,研究了探索不同散度度量即D_f 的效果。 |
在线 RL 与离线 RL
在强化学习中,训练过程中可以通过一种称为在线学习的方法生成回复。在线学习的主要优点是它从策略的最新版本中采样回复。相比之下,离线方法依赖于早期生成的回复。尽管离线方法可以通过避免在训练期间生成新回复来节省时间,但它们存在使用可能与当前策略不一致的回复的缺点
优化
- 迭代/在线偏好优化与非迭代/离线偏好优化;2. 分离SFT与对齐与合并SFT与对齐。
迭代/在线偏好优化与非迭代/离线偏好优化
仅利用收集的数据集进行对齐的过程被称为非迭代/离线偏好优化。相反,当1. 人类标注新数据或2. LLMs扮演双重角色——既生成响应又评估它们时,迭代/在线偏好优化成为可能
分离SFT与对齐与合并SFT与对齐
在RLHF中,SFT和对齐传统上以顺序分离的方式应用,这可能既繁琐又容易导致灾难性遗忘。为了解决这个问题,一些研究,如ORPO,提出了将SFT与对齐整合到一个过程中以简化微调。此外,PAFT建议同时对LLMs进行SFT和对齐的微调,然后合并结果
预备知识
损失函数
交叉熵损失
排序主要的损失函数(pointwise pairwise listwise)
这三个概念源自排序算法

point-wise
仅考虑单个query和response的关系,会把将问题转化为分类或回归问题,对于分类问题,正负例可以通过用户的点击来构造.
相当于仅考虑绝对价值和得分,忽略了对不同response的比较
pairwise
对response做一个两两比较进行二分类关系,但比较中可能出现冲突和偏差,考虑了相对关系,忽略了绝对关系
为什么RLHF用策略梯度方法,而不是DQN等
策略梯度方法
策略梯度优化
参数化策略的概率分布,易于学习参数.有目标函数

最大化轨迹期望的奖励,其中:

对目标函数求导可得:

用m个轨迹样本进行梯度近似:

常见策略及其对应策略梯度
softmax策略

策略梯度为:
观察到的特征向量减去所有动作的平均特征向量,如果奖励信号很高并且观察到的向量与平均向量相差很大,就会有增加该动作概率的强烈趋势
Gauss策略

正态分布均值:
策略梯度为:
损失函数如下:

自然策略梯度算法
传统更新的问题
Overshooting:更新跨步太大,超出了奖励峰值,落入次优策略
Undershooting:更新过慢,迟迟不能收敛到最优策略
在强化学习问题中,如果因为overshooting陷入了一个较差的策略区域,则未来的样本批次可能不会提供太多有意义的信息,用较差的数据样本再去更新策略,从而陷入了糟糕的正反馈中无法恢复。较小的学习率可能会解决这个问题,但会导致收敛速度变慢的undershooting问题
如果限制每次更新步长的上限

但同样的参数变化对不同的分布影响不同,这种方法没有考虑到分布对参数变化敏感性的差异.因此引入了二阶导数,这也是自然策略梯度的差异.
限制策略梯度更新的差异
从结果考虑,考虑策略的变化差异而非策略的参数的变化差异,引入表示分布差距的KL散度

限制更新后的策略差异

使用lagrange松弛将约束优化转为带惩罚的优化:

近似方法化简KL的运算:

与散度相比,二阶展开可以忽略不计(??), KL散度近似于二阶泰勒展开(零阶和一阶差分的计算结果为0
进一步,用fisher信息矩阵替换二阶KL导数,并不考虑所有不依赖于$\Delta\theta$的项,

fisher信息矩阵,可以表示为策略梯度的外积:

局部等价于何塞矩阵,计算效率更高.
设更新的梯度为0,求最佳更新权重:

根据
\(D_{KL}(πθ∥πθ+Δθ)≤ϵ ,\)
我们可以推出动态学习率:
可以确保每次更新的KL散度(近似)等于 ϵ 。
提取自然策略梯度,它是针对流形曲率校正的梯度

这种自然策略梯度在距离约束内给出了黎曼空间中最陡的下降方向,而不是传统上假设的欧几里德空间中的最陡下降方向。与传统的策略梯度相比,唯一的区别是与逆Fisher矩阵相乘。
最终的权重更新方案为:
无论分布的表示如何,它总是以相同的幅度改变策略
TRPO(2017)
引入重要性采样解决采样效率问题,在旧策略采样解决对新策略的估计.
引入GAE解决单步优势的方差-偏差平衡问题后,有TRPO,

首先用优势函数计算策略更新前后的预期回报差异:

强调动作的重要性.
引入折扣分布:
可以表示差异表达式为:

更新策略后的分布需要重新采样才能确定,因此,仍然使用旧策略去近似:

描述更新策略相对于原策略的预期优势称为替代优势(surrogate advantage)


We proved monotonic improvement for an algorithm that repeatedly optimizes a local approximation to the expected return of the policy with a KL divergence penalty, and we showed that an approximation to this method that incorporates a KL divergence constraint achieves good empirical results on a range of challenging policy learning tasks, outperforming prior methods.
最终有TRPO的形式:

限制了分布的相似性.(重要性采样在分布差距太大且样本不足时,估计不准确)
实验验证:
采用的方法:共轭梯度法,线搜索法
PPO(2017)
优点:样本复杂度更佳,小批量更新

adaptive惩罚法
从TRPO的惩罚系数的选择入手,当更新的散度过大,就增大$\beta$,反之则减少,$\beta$过大或过小,都会导致所谓overshooting和Undershooting 的问题.,目标是散度不要太大,对于散度太大的更新进行惩罚,
clip裁剪法

截断了重要性采样的值,限定了上下限,直接限制了策略可以改变的范围
还引入了值函数更新的误差促进critic准确估计状态值
引入熵正则化项鼓励策略探索
汇总损失函数为:


上图为对不同方式优化的前后策略插值(就是类似软更新)后的KL散度比较,可见$L^{clip}$是$L^{cpi}$的下界,其策略变动更平缓,不会距离原策略太远
 .
.

奖励模型通常是一个经过特殊微调的语言模型,其输入是生成的文本,输出是一个标量值,表示该文本的「质量」或「符合人类偏好的程度」。
DPO(简化的屌丝版本2024)
pre : bradley-terry model:成对比较,预测一个对象比另一个对象表现更好的概率
设p_i和p_j分别是能力值
一般用MLE求解
在给定一组比赛数据后,,最大化该目标函数,求出对应能力值.

DPO:目标函数为奖励参数化下等效的bradley-terry model
对于RLHF中RL结合奖励模型做微调的目标函数:

优化目标是希望每一步更新前后KL散度不要太大,且可以写成:

归一化分母:

有$\pi^\star$和$r_{\phi}$的关系

优化目标可以进一步写为:

$\pi^\star$和$r_{\phi}$的关系可写为

代入初始优化目标得到,
[!NOTE]
选择/拒绝的奖励的绝对大小实际上并不重要;重要的是,选择的奖励高于被拒绝的奖励(该模型为选择的响应分配的奖励高于被拒绝的响应)。
观察这个loss,我们知道,更关注好的response提升和坏的response相较于训练之前的概率差值(变化),的比较,这个win的差值和lose的差值的差,(相对的变化)是否变大,说明了好的response得到的概率更大了,
绝对的价值并不是那么重要,更关注不同response之间相对的价值
sigmoid使得 对于每个pair,log(p(yw))-log(p(yl)) 出现边际收益递s减
使用场景:
supervised contrastive learning
DPO and PPO for LLM
一般来说LLM是如下步骤
step 1:语料库上的知识学习,预训练与标注数据产生SFT模型
step 2:指令数据微调(听懂并回答),用一些prompt和response pair ,训练Reward model.
step 3:偏好学习:(对齐人类偏好)(听懂并回答的好) 使用PPO,DPO等RL方法,SFT为actor,reward model作对于Actor产生的prompt response进行打分,即rl中的奖励,冻结初始的sft model 参数为Reference model(SFT),用来约束后续更新产生的llm不要离初始model太远(常用kl约束),和reward model(Rw)作为备份.学到的策略,是输出文本的条件概率分布,状态空间是输入的token序列,action space是可能输出的token 的所有排列组合
Critic model用来预估总收益$V_t$
reward model 是对sft model输出的prompt-response对训练以及相应的人类打分进行t训练.对提示词与回答输出相应的得分(计算$R_t$)
[!IMPORTANT]
需要注意的是,Reward输出的$R_t$是对response的评分
Critic model在更细的粒度上修正收益,提出$V_t$
Reward/Reference Model是参数冻结的
对于PPO来说,他用到了4个模型(Actor,critic,reward model, reference model),2次训练(ppo,reward),2次推理


2个model,一个reference model,一个actor model
变量变换直接将偏好损失定义为策略的函数。因此,DPO可以使用一个简单的二元交叉熵目标来优化策略,产生一个隐含的奖励函数的最优策略
DPO没有reward如何RL?
| 计算当前策略和参考策略在生成输出上的某种差异度量,如 KL 散度(\text{KL}[\pi_\theta(y | x) | \pi_{\text{ref}}(y | x)]) 。同时结合人类偏好确定的奖励信号(即使没有显式奖励模型,也可从偏好关系中隐性获得奖励信号,如被偏好的输出对应正奖励 ),构建优化目标,例如(\max_{\pi_\theta} \mathbb{E}{x \sim \mathcal{D}, y \sim \pi\theta(y | x)} [r_\phi(x, y)] - \beta \text{KL}[\pi_\theta(y | x) | \pi_{\text{ref}}(y | x)]) ,其中(r_\phi(x, y))是根据偏好关系确定的奖励值,(\beta)是权衡系数,通过优化该目标实现策略训练 |


###
GRPO(deepseek)
核心思想:通过组内相对奖励来估计基线(baseline),从而避免使用额外的价值函数模型(critic model)。传统的PPO算法需要训练一个价值函数来估计优势函数(advantage function),而GRPO通过从同一问题的多个输出中计算平均奖励来替代这一过程,显著减少了内存和计算资源的消耗。

GRPO 与PPO 的主要区别有:
- GRPO 省略了 value function model.(rlhf中即为critic model)
- GRPO reward 计算,改成了一个q 生成多个r, 然后reward 打分。
- PPO 优势函数计算时,KL 是包含在GAE内部的。 GRPO 直接挪到了外面,同时修改了计算方法。
motivation:认为value function model 占用了额外的显存和计算资源 ,去除value function , reward 直接对单个q生成的response进行打分,归一化后,作为替代的优势函数
同时将KL散度抑制,移到了优势函数计算的外面。 KL 散度的计算也进行了改进,可以见公式4. 为了保证KL散度为正值


Instruct GPT
实际是GPT3.5
reward learning
prompt learning 和Instruct Learning
pointwise的 显式reward 模型(Bradley-Terry model),

,考虑到同一个prompt的response都具有一定的相关性, 如果完全打乱进行随机训练会导致过拟合,在同一个prompt 下回复了K个response,共有$C_k^2$win loss response对进行输入进行训练,改善了过拟合
缺点是忽略了相对之间的关系,没有说明response之间的相对得分。也就是说,对分数相似的对响应或分数差异很大的响应被对待相同。后续有人用listwise加以改进
RL训练阶段
最优的response策略由如下目标函数给出

第一项最大化奖励
第二项最小化与referennce的差距,避免策略偏离太多
第三项避免alignment tax(Alignment Tax - AI Alignment Forum),加入$\gamma\neq 0$后,避免了公共NLP数据集(即预训练数据集)上的表现降级(ppo-ptx,)
所谓「对齐税」(Alignment Tax),指的是在使 人工智能系统 符合人类偏好的过程中,所不可避免付出的性能损失或代价。在对齐后,在下游任务中的表现降级,

inter-annotator agreements rates是文本一致性的校验指标,这里在说标注者对于彼此标注的认可度和一致性
对齐指标:Helpful, Honest, Harms.
我们实现rlhf的关键是用人类的一些价值观去进行修正.
“Helpful” meant that the model should follow instructions and infer intention from a few-shot prompt or another interpretable pattern, and it was evaluated by human labelers. “Honest” referred to two metrics: (1) evaluating the model’s tendency to fabricate information on closed-domain tasks and (2) performance on the TruthfulQA benchmark [45]. “Harms” involved labelers evaluating whether an output was inappropriate in the context of a customer assistant.
helpful:遵循指示,且能推断prompt 的意图(如何评估?)
**honest **
(1)评估该模型在封闭领域任务上编造信息的倾向
(2)真实问答(TruthfulQA)” 基准测试上的表现([45] Stephanie Lin, Jacob Hilton, and Owain Evans. Truthfulqa: Measuring how models mimic human falsehoods, 2022.)
harms
“危害” 涉及标注人员评估在客户助手的情境下,某项输出是否不恰当。
效果:参数量仅为 1.3B 的 Instruct GPT,在输出质量上超越了参数量达 175B 的 GPT-3,实现了性能提升同时降低模型规模
Anthropic
[!NOTE]
inter-labeler agreement rate” 的意思是 “标注者间一致性比率”。
在很多需要人工进行标注的任务中(比如对文本内容进行分类标注、对图像进行标注等),会安排多个标注者独立去完成相同的标注工作,之后通过统计分析等手段来衡量这些标注者彼此之间标注结果的一致程度,这个一致程度用比率的形式呈现出来,就是标注者间一致性比率。较高的该比率通常意味着标注的可靠性和稳定性比较高,相应的标注结果可参考性更强。
average agreement rate
例如在多个标注者对一组数据进行标注分类,或者多个评委对参赛作品等进行评价打分等场景下,计算出每一次(每一组)的一致性比率后,再对这些比率求平均值,得到的就是平均一致性比率,它常用来综合衡量整体上不同主体之间评判、认定等方面的一致程度情况
NLP的下游任务
自然语言处理(NLP)中的下游任务是指基于预训练语言模型进一步开展,针对具体应用场景和目标的相关任务,通常需要在预训练模型基础上进行微调或专门设计来实现
数据集的构建
1
在筛选标注者方面,open AI根据筛选标注者的标签质量( agreement rate等指标),得到了76%的inter-labeler agreement rate
而Anthropic选择了更有写作技巧和,并且能与人工智能进行更具启发性讨论的众包工作者(兼职人员),很可能在判断哪些人工智能的回应最 “有帮助” 以及最 “无害” 方面具备更好的判断力.
研究者与众包标注者之间的平均一致性较低,63%,因此对标注进行筛选是必要的
2
围绕helpful和harmless,构造了两个数据集,使用偏好进行建模,其实和instruct gpt类似的pointwise reward,忽略了response之间的强弱(偏好)比较,即忽略了preference-strength information
研究方法与结果
估计不同参数规模的llm, evaluated seven different models with size ranging from 13M to 52B, following a geometric progression with increments of approximately 4×
结论是较小模型中体现了alignment tax,但有利于较大模型(13B,52B)
此外,Openai团队之前在instruct GPT分别使用了PPO和PPO-ptx,即引入了对齐税作为惩罚,Athropic的研究者认为对于规模较大的模型,仅仅使用ppo就可以在NLP的下游任务中得到很高的对齐奖励.并且认为RL训练过程中$\beta=0.001$是最佳参数
reward model
anthropic发现,奖励模型的准确度(如何评估?)和参数size成对数线性关系,参数规模越大的奖励模型越稳健.
在实际reward model训练中,他们将数据集分为训练集和测试集,分别训练了两个reward model, train 和test RM,在后续RL训练过程中,train RM用于训练中的环境,Test RM用于策略评估.
且发现, train RM和Test RM在初期的相似后,出现了分歧,Test RM分数较低,可以认为是出现了过拟合
| 在强化学习策略训练期间,研究人员发现奖励与 DKL(πθ | πref)之间存在线性趋势。然后,作者还运用了分布外(OOD)技术来检测并拒绝不合理的请求。最后,他们探索了一种在线训练模式,通过与众包工作者互动获取新的人类偏好数据,每周对奖励模型和强化学习策略进行更新 |
iterative /online rlhf(迭代策略优化)
[!IMPORTANT]
偏好判定源(preference oracle)” 通常是指能够确定不同输出内容(比如不同的文本回复、不同的模型生成结果等)相对优劣偏好情况的一种机制、系统或者信息来源
离线的学习方法由PPO类型和DPO类型,我们有各种各样的学习方法来结合
使用静态数据集,但缺点在于,response的产出来自llm,但偏好比较来自标注者或其他ai agent,无法给出偏好判断的机制
可能导致分布内过度优化,数据集只是prompt-response的一部分样本集合,面对分布外数据表现欠佳
解决上述问题需要llm根据实时策略生成的prompt-response对进行在线微调,从偏好判定源获取偏好反馈,然后将其反馈给策略
学习步骤
the iterative learning was divided into two parts
偏好判定源学习:在一个离线的大规模多元Preference数据集上训练一个llm,用于对其他prompt response对进行评估


结论
大量经验评估表明,通过在线RL培训的政策,离线RL的策略结果有所改善
下面介绍RLAIF
使用ai偏好,减少获取人类偏好数据集的潜在cost
Direct Human Preference Optimization
直接依靠人类偏好优化策略,而不是显式的奖励信号
SliC-HF
采用序列似然校准方法进行对齐
采用正则化的max-margin loss:

$\delta$是区分desired response和不desired的边界,
P是偏好打分
正则项 希望参数不偏离reference太远
RSO拒绝采样优化
核心:统计拒绝采样
解决训练数据与最佳策略期望的数据之间的分布不匹配,从而解决了离线偏好优化方法(例如SLIC和DPO)中的局限性
DPO(之前提过)
局限性

拓展dpo损失函数用于处理标注中的噪声

基础模型是预训练SFT好的llm,偏好数据是对问答对的人类偏好标注.
在 DPO 中,偏好数据用于直接优化模型策略。但如果基础模型输出的回复风格、话题覆盖等与收集偏好数据时所基于的样本存在较大差异(即分布偏移 )
[!IMPORTANT]
训练机制是怎样的?
DPO中基础模型的输出为什么会与偏好数据的样本有较大差异
答:
训练数据来源和规模差异:
基础模型(如 GPT - 3、LLaMA 等 )通常基于海量的通用数据进行预训练,这些数据涵盖了广泛的领域、主题和文本类型,目的是让模型学习到普遍的语言知识和语义理解能力。
偏好数据是针对特定任务或场景 ,通过人类标注者对模型输出进行评估和比较得到的。其规模相对基础模型的训练数据要小很多,并且收集过程往往聚焦于特定的任务需求。
数据分布和特征差异
基础模型训练数据的分布较为宽泛,旨在捕捉语言的一般性规律和广泛的语义表示。这使得基础模型输出具有多样性和通用性,但也导致其在特定任务上可能不够精准
偏好数据反映的是人类对于模型输出在特定任务或场景下的具体偏好,具有较强的针对性和任务导向性。其数据特征往往围绕着任务目标进行界定
模型优化目标差异
预训练阶段的基础模型以预测下一个 token 等通用目标进行优化,旨在学习语言的统计规律和语义表示,以适应广泛的自然语言处理任务。这种优化目标使得基础模型在面对具体任务时,其输出可能无法直接满足任务需求。
偏好数据是为了使模型输出符合人类在特定任务上的偏好而收集的,其对应的优化目标是让模型生成的内容在特定任务场景下更受人类认可。
标注和评估过程的主观性
基础模型在预训练阶段没有直接涉及人类的主观评估和偏好判断,只是基于大规模数据进行无监督或自监督学习。
偏好数据的收集依赖于人类标注者的主观判断。不同标注者可能存在理解差异、个人偏好差异等。
DPOP :smaug
之前研究的问题:
response的得分同时增大减少,只需要差距扩大即满足优化目标
直接偏好优化(DPO)损失函数旨在最大化期望响应与非期望响应之间的差异,但这种方法存在问题。它可能导致期望响应和非期望响应的奖励同时增加或减少,只要二者差异在扩大。作者从理论上证明两种响应的奖励可能同时降低

加入的正则项是关键,希望该项变小,即避免了期望response的奖励减少,这是因为除了标准的 DPO 损失外,偏好生成的对数几率被激励相对于参考模型得到改善
β-DPO
解决了什么问题?
对参数$\beta$敏感:性能对其权衡参数($\beta$)(与偏好数据质量相关)的微调敏感,原因有二:一是$\beta$最优值随偏好数据质量变化,需动态调整;二是现实数据集常含异常值干扰优化
技巧
批量$\beta$动态调整:
其中(M_{i})是个体奖励差异,(M_{0})是一个阈值,(\alpha)是一个缩放因子
$\beta$引导的数据过滤:基于奖励差异概率模型过滤异常值,减轻其影响
效果

理解
\beta越大,说明这批次样本对学习越重要,奖励差异越大的越放大\beta
IPO
motivation
Azar等人指出RLHF和DPO容易过度拟合,并引入了身份偏好优化(IPO)作为解决这一问题的方法
RLHF的两个关键假设:1. “成对偏好可以用点态奖励替代”,和2. “在这些点态奖励上训练的奖励模型可以从收集的数据泛化到策略采样的分布外数据
然而在确定性条件下 P (yw > yl) = 1.

随着该值趋向正无穷,由β施加的KL散度约束的有效性减弱。因此,目标函数转向最大化累积奖励,可能导致过度拟合
做法
引入了该函数避免了基于点态奖励的BT模型转换,并专注于优化偏好概率的非线性函数

优化第一个策略$\pi_{\theta}$


作者认为$\Psi$的非线性导致了过拟合,因此设为x,得到目标函数

有损失函数

该损失函数可以避免BT模型将点态奖励转换为偏好概率
实验结果
这一新导出的损失函数可以直接进行优化,以获得最优策略,有效缓解过拟合问题。实验在一个基础的数学用例上进行,结果表明当惩罚系数β 足够大时,IPO 成功避免了过拟合,而 DPO 则倾向于过拟合。然而,通过添加噪声改进的 DPO 预计能充分解决这一问题。最后,需要进一步在下游 NLP 任务中的用例来验证 IPO 方法的优势
sDPO(逐步DPO)
motivation
作者假设参考模型为 DPO 提供了下界,暗示一个改进的参考模型可以为 DPO 训练提供更优的下界,意思是原来的参考model太拉了,我们改进一下,让下界更好
做法
核心:它将偏好数据集分段并逐步使用。在每个阶段,应用 DPO,生成的部分对齐模型成为新的参考模型
将数据集分段,分步对齐,每一步对齐得到的model 都作为下一步的reference model
实验效果
SOLAR 10.7B [60] 被用作参考模型。随后,在sDPO过程中采用了两个数据集:OpenOrca(约12K样本)[61] 和 Ultrafeedback Cleaned(约60K样本)[62],其中OpenOrca用于第一步,Ultrafeedback用于第二步。使用了四个任务,即ARC [55]、HellaS WAG [56]、MMLU [63] 和 TruthfulQA [45],并且它们的得分超过了DPO。相比之下,由于Winogrande [64] 和 GSM8K [65] 本质上是生成任务,与之前考虑的多项选择任务不同,因此被排除在外
sDPO是否会对生成任务产生负面影响,以及其他疑问

GPO(广义偏好优化)

第二步由假设了
并且Tylor展开而来
具体还得看一下原文
Token level DPO
尽管在RLHF中,Reward model对prompt-reponse 打分,但从MDP的角度思考,往往对于每一个动作都需要奖励,在RLHF中的mdp中每一个动作即为输出的token,一些token组成了response
DPO: from r to Q
| DPO被概念化为一个Bandit问题(多臂老虎机)而非token级MDP [39],将整个响应视为单臂以接收奖励。在[17]中,作者证明了DPO能够执行token级信用分配。(怎么证明?)在token级MDP的背景下,它被定义为M=(S, A, f, r, ρ0_0),其中S表示状态空间,A表示动作空间,f(s | a)描述了给定动作的状态转移,r表示奖励函数,ρ_0表示初始状态分布。token级MDP在RL的最大熵设置框架内被公式化,如公式20所示。 |
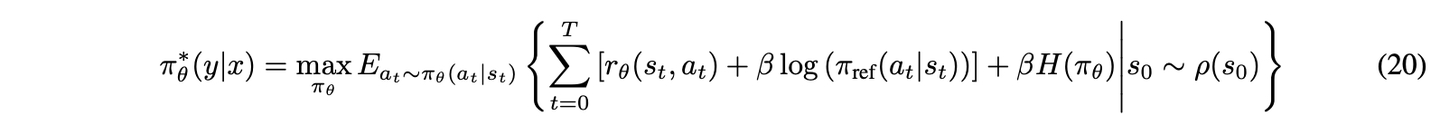
函数V_θ ( s_t ) 在Eq. ~ 21 中阐述。在最大熵强化学习的背景下,最优 Q 函数Q_θ ( s_t, a_t ) 与最优值函数之间的关系如下:
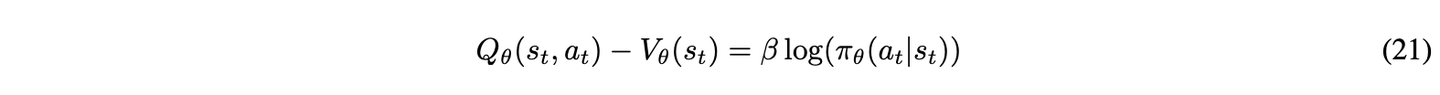
贝尔曼方程在式 22 中展示。
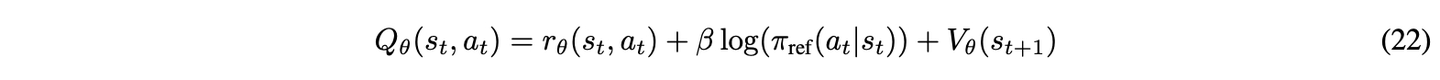
将式 22 中的Q_θ ( s_t, a_t ) 代入式21 得到:

。 此外,通过对两边求和并利用V{\theta} ( s{T} )=0,累积奖励可以重新表示为如式 23 所示。
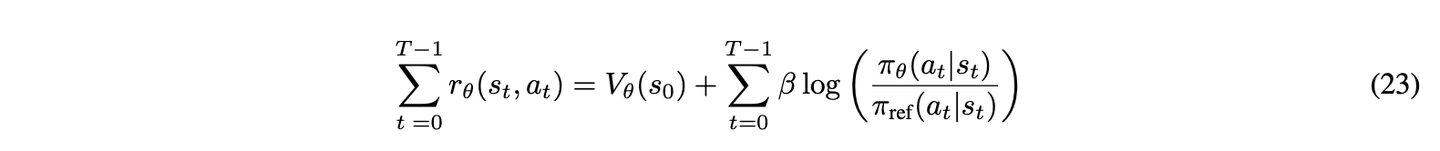
进一步有:bradle terrey模型得到的偏好概率

最终,传统的将整个响应视为单一实体的bandit问题被重新定义为token级 MDP,其中每个token生成被赋予奖励。
结论:
大量实验证明了 DPO 在token级 MDP 中的有效性。最初,作者成功利用token级奖励识别了在给定提示x 的情况下 LLM 响应y 中的错误修改。然后,通过采用带有token级奖励的束搜索,作者生成了更高质量的响应,结果表明增加束大小显著提高了响应质量。最后,作者证明了在最大熵 RL 期间,当使用 SFT 微调的模型作为参考模型时,期望和非期望响应的隐式奖励都会减少。
“beam” 指的是束搜索(beam search)中的 “束宽”。束搜索是一种用于寻找最优解的启发式搜索算法,常用于自然语言处理任务,如机器翻译、文本生成等。
在文本生成场景下,模型在每个时间步会根据当前状态预测下一个可能的词。普通的贪心搜索每次只选择概率最高的那个词作为输出,但这可能会导致模型过早地陷入局部最优解,生成的文本质量不高。而束搜索则会在每个时间步保留概率最高的前 k 个词(k 就是束宽 beam size),形成 k 条搜索路径,然后基于这些路径继续向前搜索。随着搜索步骤的推进,不断扩展这些路径,最后从所有路径中选择概率最高的那条路径作为最终输出。
在上述文本中提到,通过采用带有标记级奖励的束搜索,作者生成了更高质量的响应,并且增加束宽显著提高了响应质量。这表明束宽越大,搜索过程中保留的候选路径越多,模型在生成文本时能够考虑更多的可能性,从而有可能生成更符合期望、质量更高的文本
疑问:增加beam size 会不会导致计算量的显著增加??
TDPO
motivation:
The authors discovered that in the DPO process, the generative diversity of LLM was deteriorated and the KL divergence grew faster for less preferred responses compared with preferred responses, and they proposed token-level DPO (TDPO) to solve these problems [18]
方法:
在原始 DPO 中应用了反向 KL 散度,而在token级 DPO 中应用了顺序前向 KL 散度

每一个reponse中的token的参与到状态价值的评估的,作为状态,既有prompt,也有该response中该token之前的token作为状态,动作是当前的token
对于token级别的DPO问题,奖励衰减设置为1,即没有奖励衰减,总奖励可以表示为公式25

基于目标函数,Q值与最优策略之间的关系可以推导为公式26。

Z值两个项不能像在DPO中那样被抵消。

为了解决这个问题,作者提出了序列KL散度,如公式27所示。

基于定义的序列KL散度,当应用B T 模型时,如公式28所示。



实验与结论:
在实验中,作者使用了GPT-2 Large[ 6 7 ] 作为基础模型,并在IMDB [54]、Anthropic HH [3] 和 MT-bench [58] 数据集上进行了评估。他们的实验显示,TDPO,特别是带有停止梯度的版本,优于DPO。
Iterative/Online DPO
在DPO中,所有可用的偏好数据集都被用于对齐LLMs。为了实现LLMs的持续改进,应实施迭代/在线DPO,这提出了一个有趣的问题:如何高效地收集新的偏好数据集
Iterative/Online DPO: Self-Rewarding Language Models
方法
作者断言:“为了实现超人的智能体,未来的模型需要超人的反馈来提供充分的训练信号”。在这一论断的指导下,他们提议使用大型语言模型(LLMs)作为评估提示响应的裁判。此外,他们的目标在于“开发一个在训练期间处理所有期望能力的智能体,而不是将它们分割成不同的模型”。因此,同一个LLM被用于“指令跟随:给定一个描述用户请求的提示,生成高质量、有帮助(且无害)的响应”以及“自我指令创建:生成并评估新的指令跟随示例以添加到其自身的训练集中”。 在“自我指令创建”阶段,生成了 K 个候选响应,LLM作为裁判对这些 K个响应进行评估。评估基于五个指标:相关性、覆盖率、有用性、清晰度和专业性,评分范围可达5分。得分最高的响应被选为首选响应,而得分最低的则被视为非首选。在“指令跟随”训练过程中,使用DPO(直接偏好优化)来训练LLM,使其与生成的偏好数据集保持一致。
实验与结论
进行了大量实验,利用Llama_2 70B作为预训练的大型语言模型(LLM)[68]。研究者进行了三轮自我奖励训练。该研究的一个主要局限是没有确定迭代最佳终止点的方法。它没有解释为什么三轮迭代应被视为足够,也没有讨论为什么额外迭代可能不会带来进一步的好处。模型M_1, M_2 和M_3 分别在经过一轮、两轮和三轮DPO训练后得出。在评估中,M_2 取得了55.5%的胜率,而M_1 仅取得了11.7%的胜率。另一方面,M_3 对M_2 的胜率分别为47.79%和12.5%。在AlpacaEval中也观察到了类似趋势,展示了迭代/在线训练的益处。在AlpacaEval [40]中,进行了包括健康和专业等多个子任务。 总体上,LLM在不同任务上的表现随着更多迭代而提升,特别是在稳定性方面。模型M_1 和M_2 在各任务间表现出更多变异性,而M_3 显示出更大的鲁棒性。MT-Bench [58]的结果有所改善,而NLP基准测试的性能下降。研究者认为这种下降是由于训练数据基于Open Assistant提示,这可能与NLP基准任务不相关。然而,论文质疑这种差异是否表明过拟合而非数据集分布不一致,特别是在LLM广泛预训练于大型文本语料库的情况下。值得注意的是,NLP基准测试的性能随着更多迭代而下降。这引发了对某些任务改进是否以牺牲其他能力为代价的担忧。最后,研究者评估了奖励模型,发现大多数指标随着更多迭代而改善,除了“5-bestq_o”指标,该指标先增加后减少,但仍高于初始值。这进一步强调了确定迭代/在线DPO最佳终止点的关键重要性。
Iterative/Online DPO: CRINGE
motivation:
基于二元反馈,一种有前景的方法是对比迭代负生成(CRINGE)损失[69]。CRINGE损失旨在分别处理正负响应
二元反馈
KTO和DRO,专注于利用二元反馈来对齐LLMs
KTO
motivation
因此,在二元数据上增强对齐可以显著加速整个对齐任务的进程。
理论
理论阐明了人类在不确定事件下做出决策时,由于损失厌恶,并不会最大化期望值。卡尼曼和特沃斯基的前景理论的函数形式如公式31所示。

其中,z_0表示参考点,z代表实际结果。价值函数v ( z )将结果相对于参考点z-z_0的价值映射为感知价值,表明人类对损失的感知大于收益。该函数有两个参数:alpha控制函数的曲率,lambda调节陡度。lambda反映了损失厌恶,通常大于1。这一方程概括了人类的损失厌恶,由此产生的损失函数被称为人类感知损失(IIALOs)。
诸如SLiC [11]、PPO[ 7 2 ]、DPO[ 1 2 ]和KTO [21]等技术都属于HALOs范畴。作者认为,HALOs通常优于非HALOs。
意思是:人类更厌恶风险,同样大小的损失和收益,对损失更敏感,这类技术,提高了损失的权重
做法
从修改后的效用函数中,可以得出KTO的损耗函数,如等式中所示。 其中 所需和不希望的响应分别表示λd和λu。
使用所有提示及其相应响应的平均奖励估算$z_0$
第一个是损失函数,将reward估计为 ,这是DPO的做法.
,这是DPO的做法.

实验
为了评估KTO的性能,作者测试了两类模型:Pythia 1.4B、2.8B、6.9B、12B 和Llama 7B、13B、30B [68],使用’GPT-4-0613’ [4]进行评估。此外,从UltraFeedback [62]中的偏好数据中提取了二进制数据,期望数据转换为+1,非期望数据转换为-1。值得注意的是,尽管二进制数据易于获取,但由于其主观性和潜在的噪声,作者并未对其进行测试。在这种情况下,过滤出不合理的数据提出了一个更有趣的挑战。
结果
作者发现,当lambda_D=lambda_U 时,在下游任务如MMLU、GSM8k、HumanEval和BBH中实现了最佳性能。这表明对收益或损失没有显著的厌恶感。鉴于这种缺乏厌恶感,卡尼曼和特沃斯基的前景理论的必要性受到了质疑。结果显示GSM8K有显著提升,而其他任务则有轻微改进。进一步探讨这一现象将是有益的。
Direct Reward Optimization (DRO)
motivation
有直接偏好优化,也有直接奖励优化
直接奖励优化(DRO)[22]旨在使用单轨迹反馈数据(如二元反馈,例如点赞或点踩)来对齐大型语言模型(LLMs)。这种方法旨在利用更易获得的数据,相比于传统对齐技术(如DPO)中使用的稀缺成对偏好数据。 DRO建立在RLHF中使用的标准KL正则化策略优化框架之上,如公式5所示。根据目标,最优策略可以表述为公式35所示。

通过重新构建策略与奖励之间的关系,可以推导出公式36。

最终,DRO的损失函数可以通过均方误差推导出来,如公式37所示。

优势
种表述具有几个优势。它直接优化策略,无需学习单独的奖励模型。此外,它适用于单轨迹数据,这类数据比成对偏好数据更为丰富。最后,它具有独特的全局最优解( π^, V^}),可以独立优化π 和V。 然而,估计V ( x ) 被证明是具有挑战性的。因此,它使用神经网络进行近似。DRO-V,作为DRO的实际应用,联合优化了一个策略网络和一个价值网络。它结合了离线策略学习和价值函数学习,因此使用了后缀-V。策略网络和价值网络的梯度更新如下:

常用评估实验整理
| 常用实验 | 实验目的 | 数据集 | 评估方法 | 评估指标 |
|---|---|---|---|---|
| RLHF/PPO 系列实验 | 探究通过人类反馈微调 LLM,使其在多任务中符合用户意图的效果 | SFT 数据集(含标注者示范数据,训练 SFT 模型)、RM 数据集(模型输出的标注者排名数据,训练奖励模型)、PPO 数据集(用于 RLHF 微调的提示数据);Anthropic 研究中自制的 “helpful” 和 “harmless” 数据集 | 1. 人工标注评估:让标注者评估模型输出在 “Helpful”(如是否遵循指令、推断意图)、“Honest”(如在封闭域任务中是否编造信息、在 TruthfulQA 基准测试中的表现 )、“Harms”(如作为客服助手时输出是否合适)等方面的表现。2. 模型性能评估:对比不同模型在 NLP 基准测试中的性能变化,观察 “alignment tax” 现象 | 1. 标注者间一致性:衡量标注者评估结果的一致性程度。2. 模型性能指标:如在 TruthfulQA 基准测试中的得分,以及在不同 NLP 任务(如文本生成、问答等)中的准确率、F1 值等;在 “Helpful”“Honest”“Harms” 评估中的用户偏好率,例如 InstructGPT 中 1.3B 参数模型在与 175B GPT - 3 对比时,输出被偏好的比例 |
| RLAIF 实验 | 验证利用 AI 反馈替代部分人类反馈进行 LLM 对齐的可行性和效果,对比人类与 AI 反馈的有效性 | 1. Reddit TL;DR(用于测试总结任务)2. OpenAI’s Human Preferences(用于测试有用性对话生成任务)3. Anthropic Helpful and Harmless(HH; harmless)Human Preferences(用于测试无害性任务) | 1. AI - labeler alignment:计算 AI 标注与人类标注的一致性程度。2. win rate:比较两个候选响应时,某一响应被人类标注者选择的概率。3. harmless rate:人类评估者认为无害的响应比例 | AI 与人类标注的一致性分数、不同模型在各任务中的胜率、无害率 |
| 直接人类偏好优化实验(如 SLiC - HF、DPO 等) | 探索直接基于人类偏好优化 LLM 策略的方法,简化对齐过程,提高计算效率和模型性能 | 1. Reddit TL;DR(用于总结任务)2. Anthropic HH(用于对话任务)3. IMDB 数据集(用于控制情感生成任务)4. 部分研究自制的包含小编辑距离数据的数据集(如修改后的 ARC、Hellaswag、Metamath ) | 1. 对比实验:与传统 RLHF/PPO 方法对比,评估新方法在相同任务上的性能。2. 消融实验:研究模型中不同组件或参数设置对性能的影响 | 1. 模型性能指标:在总结任务中的 ROUGE 指标,对话任务中的胜率,情感生成任务中的准确率等。2. 计算资源指标:如内存占用、训练时间等,例如 SLiC - HF 使用的内存仅为 PPO 训练范式的 0.25 |
| 二进制反馈实验(如 KTO、DRO) | 研究利用二进制反馈(如 “thumbs up”“thumbs down”)进行 LLM 对齐的效果,加速对齐过程 | 从偏好数据转换而来的二进制数据(如 UltraFeedback 中的数据,将期望数据转换为 +1,非期望数据转换为 -1 );DRO 实验中使用的单轨迹反馈数据(如二进制反馈) | 1. 模型性能评估:在多个下游任务(如 MMLU、GSM8k、HumanEval、BBH )中评估模型性能。2. 对比实验:与其他对齐方法(如 KTO 与 DRO 对比)进行比较 | 1. 任务准确率:在各下游任务中的准确率,如 KTO 在 GSM8K 任务中的准确率提升情况。2. 损失函数值:如 DRO 中的损失函数值,用于衡量模型训练的效果 |
| 合并 SFT 和对齐实验(如 ORPO、PAFT) | 解决传统 SFT 和对齐顺序应用时的繁琐和灾难性遗忘问题,探索更高效的整合方式 | UltraFeedback 数据集(用于 ORPO 和 PAFT 实验中的偏好数据) | 1. 模型性能评估:在多个评估基准(如 AlpacaEval2.0、IFEval、MT - Bench )上评估模型性能。2. 对比实验:与传统顺序应用 SFT 和对齐的方法,以及其他类似整合方法(如 ORPO 与 DPO 对比)进行比较 | 在各评估基准上的得分,如 PAFT 模型在 Huggingface Leaderboard 上 7B 模型中的排名和得分 |
| 长度控制和无参考模型 DPO 实验(如 R - DPO、SimPO、RLOO) | 解决 LLMs 输出过于冗长的问题,探索无需参考模型的 DPO 方法,提高模型性能 | 1. Anthropic RLHF HH2. Reddit TL;DR3. AlpacaEval24. MT - Bench5. Arena - Hard 基准 | 1. 对比实验:与标准 DPO 等方法对比,评估新方法在输出长度控制和模型性能方面的表现。2. 消融实验:研究新方法中关键组件(如 SimPO 中的长度归一化策略、奖励裕度 γ )对模型性能的影响 | 1. 输出长度指标:如平均输出长度。2. 模型性能指标:在各任务中的胜率、准确率等,如 R - DPO 在 Anthropic RLHF HH 数据集中的胜率变化 |
| 列表 wise 偏好优化实验(如 LiPO、RRHF、PRO) | 研究直接使用列表 wise 偏好数据集优化 LLMs 性能的方法,提高数据利用效率 | 1. Reddit TL;DR2. AnthropicHH3. OpenAssistant 任务 | 1. 对比实验:比较不同列表 wise 偏好优化方法之间的性能差异,以及与传统 pairwise 偏好方法的差异。2. 模型性能评估:在多个任务中评估模型性能 | 1. 模型性能指标:在各任务中的排名、得分等,如 LiPO 实验中不同损失函数下模型在各任务中的表现排名。2. 数据利用指标:如对列表 wise 偏好数据中得分信息的利用效率 |
| 负偏好优化实验(如 Negating Negatives、Negative Preference Optimization、Contrastive Preference Optimization) | 利用 LLMs 生成的输出作为期望响应,通过负偏好优化减少不期望响应,提高模型性能 | 1. PKU - SafeRLHF 数据集(用于 Negating Negatives 实验 )2. 机器翻译任务中自制的数据集(用于 Contrastive Preference Optimization 实验 ) | 1. 模型性能评估:在相关任务(如减少有害响应任务、机器翻译任务)中评估模型性能。2. 对比实验:与其他方法对比,观察负偏好优化方法的效果 | 1. 有害响应减少比例:如 Negating Negatives 实验中模型输出有害信息的减少比例。2. 任务性能指标:在机器翻译任务中的 BLEU 得分等 |
| Nash 学习实验(如 Nash Learning from Human Feedback、SPPO、DNO) | 解决传统基于点 wise 奖励和 BT 模型的方法在处理人类偏好时的不一致问题,提高模型对齐效果 | 1. PaLM 2 Large(用于 Nash Learning from Human Feedback 实验中的文本总结任务 )2. UltraFeedback(用于 SPPO 和 DNO 实验 ) | 1. 对比实验:与传统 RLHF 等方法对比,评估 Nash 学习方法的性能。2. 模型收敛性评估:观察模型在训练过程中的收敛速度和稳定性 | 1. 任务性能指标:在文本总结任务中的 ROUGE 指标,在 AlpacaEval 2.0 等评估基准上的得分。2. 收敛指标:如收敛所需的迭代次数、收敛过程中的损失函数变化 |
| Beyond Reverse KL Divergence 实验 | 探索替代反向 KL 散度的方法,解决 LLM 对齐过程中响应多样性降低的问题 | 1. IMDB - sentiment2. Anthropic HH3. MT - bench | 1. 对比实验:对比不同散度(如 α - 散度、正向 KL 散度、Jensen - Shannon 散度与传统反向 KL 散度)在 LLM 对齐中的效果。2. 模型性能评估:在多个任务中评估模型性能 | 1. 奖励指标:模型获得的奖励分数。2. 多样性指标:如生成响应的熵值,用于衡量响应的多样性 |
关键问题
不同奖励模型对 LLM 对齐效果有何影响?
- 显式奖励模型通过在预训练 LLM 上微调得到,能直接为提示和响应分配奖励,但训练过程复杂;隐式奖励模型如 DPO,通过建立最优奖励模型和最优策略的映射,简化了训练流程。点 wise 奖励模型基于 Bradley - Terry 模型获取奖励分数,而偏好模型能直接建模偏好概率,后者在处理不一致的人类标注时更具优势。response级奖励模型基于整个响应给予奖励,token级奖励模型则在每个动作后给予奖励,更符合马尔可夫决策过程,有助于在每个动作上实现对齐。
RLAIF 与 RLHF 相比,在实际应用中有哪些优势和挑战?
- 优势:RLAIF 利用 AI 反馈,降低了获取人类偏好数据集的成本,并且随着 LLM 能力提升,能收集更准确的 AI 偏好数据集,在无害性任务上表现更优。
- 挑战:在生成有益反馈方面,目前仍主要依赖人类标注,因为生成有益响应比识别有害响应更具挑战性;此外,RLAIF 在生成总结等任务时,可能出现生成内容连贯性不如 RLHF 的情况,需要进一步系统性分析。
为什么说 DPO 在处理数据分布变化时存在局限性,如何改进?
- DPO 的损失函数仅关注最大化期望和非期望响应之间的差异,可能导致期望响应奖励降低或非期望响应奖励增加,且对基础模型输出和偏好数据之间的分布变化敏感。当训练数据和偏好数据集不匹配时,性能会下降。改进方法包括采用迭代 DPO,利用最新的策略模型生成新响应,并使用批评(可以是单独的奖励模型或自奖励设置中的相同策略网络)进行偏好标注,以减轻分布转移问题,提升性能。